从一个状态栏到一套框架:AI 如何改变了软件的写法
如果你在其他平台看到这篇文章,这可能不是最终版本。为了获得更好的阅读体验(包含最新的评论讨论和勘误),欢迎移步原文
随着 LLM 编码能力的飞速提升,结合我近期的观察,技术圈似乎正在向同一个方向演进:利用 AI 构建高度客制化的个人软件。
这一趋势的背后有两个主要推手。首先,不少开源项目在大量接收 AI 生成的 PR 后,代码质量出现了肉眼可见的下滑——与其在泥沙俱下的代码海里做 Code Review,不如自己来。其次,大家逐渐意识到,与其苦等上游更新,自己 Fork 甚至从零重写来得更快,而且更贴合自己的实际需求。多年前人人皆可写软件的设想,似乎正以一种始料未及的方式悄然成真。
这也引发了我的深思:在 AI 时代,什么样的软件形态才是真正的未来?
从一个状态栏插件说起
最近因为订阅额度紧俏,我开始尝试在 pi 中使用 deepseek 作为一些简单的任务的替代品来节约 token 的使用,之所以使用 pi 而不是直接在 codex 或是 claudecode 里接入 deepseek 的原因有两点:
- codex 和 claudecode 我用的是订阅计划,切换模型很麻烦,需要另外下载一个新的软件来实现切换的功能
- 正如前文所说,codex 和 claudecode 的 harness 我有很多不满意的地方,使用中也堆积了很多槽点
经过一番物色之后,我选择了pi,因为它的实现最简单,也暴露了足够的接口可以自己定义实现细节(尽管其中一些接口的定义很奇怪,感觉会堆成屎山)。
开始使用之后,我就需要对其做一些改造,最先让人想动手的自然是外观——感知层面最直观,pi 的 statusline 相当简陋,所有信息都缩成一团。

官网提供的示例虽然看起来有模有样,但在我看来,里面的部分信息显得冗余,而我真正想添加的自定义信息又无从下手。我在官方的插件列表里搜刮了一圈,也没找到一个称心如意的(也可能是我漏掉了)。最后勉强找到了一个 pi-bar,但是这个插件的作者不知道为啥省略了大量关键信息,仅提供的几个基础选项也全是被写死的,毫无修改弹性;更离谱的是,里面居然还塞进了一个 AI 总结功能,导致整个插件变得异常臃肿。于是我决定在其基础上进行改写,这就有了 pi-info。
FUN FACT: 其实我最初打算将它命名为
pi-statusline。这个名字更直观,毕竟用过 claudecode 的人都对 Statusline 这个称呼很熟悉。但在发布时我才发现,这个名字已被占用。转念一想,statusline打字确实有些费劲,最终决定将其改名为pi-info。不过说实话,我至今对这个名字都不算特别满意……
pi-info 最大的灵感其实来自于 claudecode 的 statusline 的设计,cc 的 statusline 实际上就是一个会被自动加载的脚本文件,用户可以使用 agent 对其进行自由编辑以决定展示的信息,但是这样也太简陋了!你只能通过编辑难以阅读的 sh 脚本来决定展示信息,这一点也不用户友好,于是我进行了一点改造,将所有展示的信息划分为元素以及连接符,又从 starship 中寻找了一些灵感,以一套模板语法对元素进行风格化,这样用户就能通过简单的配置文件对 statusline 进行自由改造了,如下所示。
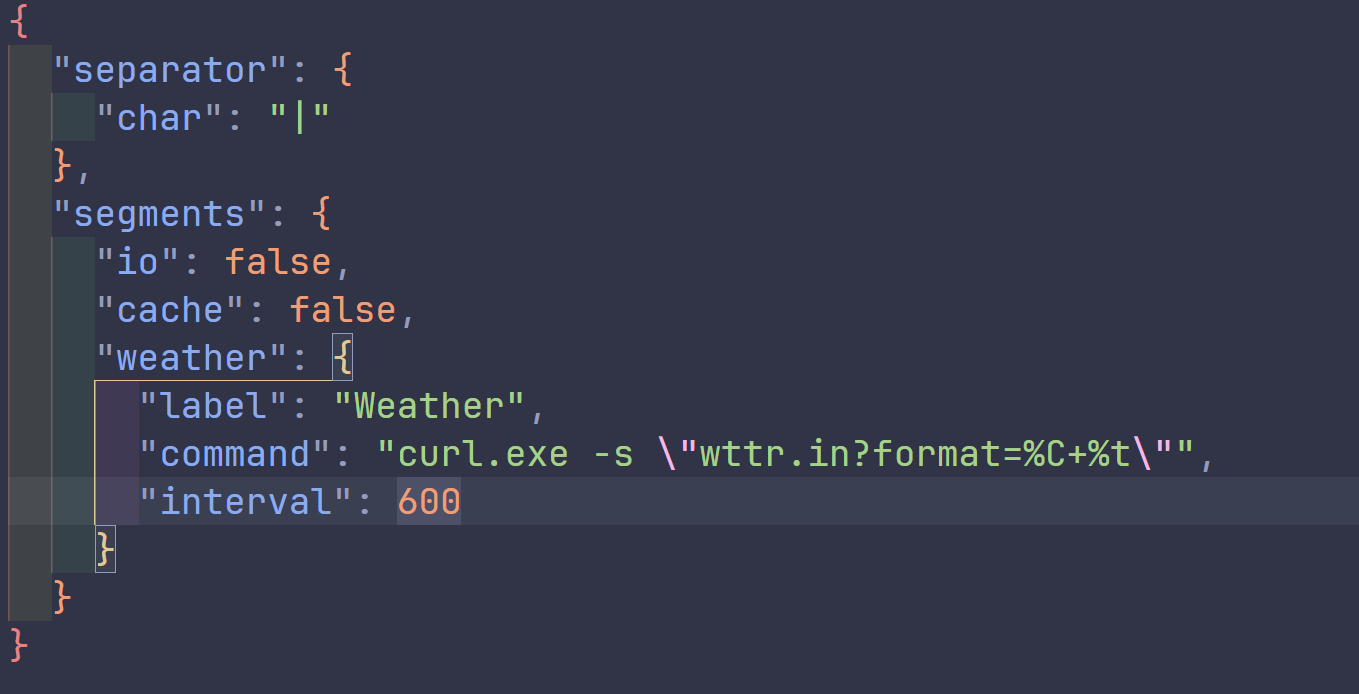
跨越"高定制性"的门槛
写完之后我不禁开始思考:当定制一个状态栏从"读文档、写脚本"变成了"说一句话",这件事意味着什么?
未来我们需要的,究竟是怎样的软件形态?
我觉得 pi 以及我写的这个插件提供了一个很好的范例。每个人都有高度个性化的工作流,因此,最好的软件应该是一个完善的底层框架——它只需提供一套够用的默认预设,并暴露出足够丰富的接口设施,允许用户将自己的逻辑代码"注入"其中。
在过去,这种"高可定制性"往往意味着极高的学习成本——看看 Vim 和 Emacs 就知道了,哪怕只是简单地修改一个状态栏,也需要你去翻阅晦涩的文档、学习专属的脚本语言。这让大部分普通用户望而却步,只能被迫接受开发者教你做事的默认逻辑。
但 LLM 的出现彻底改变了这一现状,它填平了这道鸿沟。
如今,我们不再需要亲自去啃那些 API 文档。只要软件提供了清晰、结构化、易于机器阅读的接口(比如我刚才提到的那套模板语法),LLM 就能完美充当那个"懂代码的私人管家"。我只需要用自然语言对 DeepSeek 或 Claude 说:“把这里的时间格式改成 24 小时制,前面加上一个时钟的 emoji,并且根据 CPU 的占用率改变颜色”,它就能瞬间生成对应的配置文件。
AI 时代的软件架构核心:AI-Native
我在这里说的 “AI-Native”,指的是软件在架构层面就被设计为可以被 AI 理解、操作和集成,而不仅仅是在表面上接了一个 AI 聊天框。这就引出了我对未来 AI 时代软件形态的进一步猜想:AI 友好的底层架构将比大而全的 UI 交互更重要。
未来的优秀软件,其核心竞争力可能不再是堆砌了多少个开箱即用的功能按钮,而是:
- 高度的模块化与解耦:核心逻辑与前端展示彻底分离。LLM 在理解小上下文时远比处理一个大单体代码库精准——模块化意味着每一次 AI 介入只需要处理它关心的那个局部,出错的概率和影响范围都更可控。
- 声明式且易于生成的配置:清晰的语法或 Schema 设计,让 AI 能够精准输出而不产生幻觉,最好携带一套语法 checker 让 AI 能及时验证。一套严格的 Schema 相当于给 AI 配了一根护栏——它知道边界在哪,生成的内容就不会跑偏。
- 友好的容错机制:既然代码是 AI 生成的,出错在所难免,软件需要提供一个安全且足够强大的兜底机制。比如加载失败时静默回退到默认配置、界面渲染异常时自动隔离出错模块——这些安全措施让用户可以无心理负担地频繁试错,而这正是 AI 驱动迭代的节奏所需要的。
当然,强调底层架构并不意味着交互体验不再重要,而是说交互本身也应当是高度可塑的。开发者大可以去精心打磨一套足够优秀的默认交互作为基底,但在此之外,务必要把最终决定权交还给用户,为他们留下充分的自行调整与魔改空间。
当软件的定制门槛从“学一门 DSL、读半本文档”降低到“说一句话”,个性化就不再是少数极客的特权,而是每个普通用户的日常操作。回到文章开头提到的开源软件被低质量 AI PR 淹没的现象,这实际上就是旧有的“大一统”协作模式在 AI 时代的阵痛——既然用 AI 手搓一个完美契合自己工作流的工具(或是对上游项目进行魔改)的时间,比你去给上游提 Issue、写 PR、等 Code Review、等合并发版的时间还要短得多,那我们为什么还要去凑合使用别人定义的公共版本呢?