
论文阅读:The Google File System
如果你在其他平台看到这篇文章,这可能不是最终版本。为了获得更好的阅读体验(包含最新的评论讨论和勘误),欢迎移步原文
GFS 是什么
GFS 是 Google 为了应对海量数据增长,通过分布式软件架构抵消廉价硬件的不可靠性,并针对其特定业务(大文件追加、流式读取)量身定制的高扩展存储系统。
预设的情景提到 Google 的大多数场景都是顺序读,这是什么场景?
Google 早期的大量任务(如构建搜索索引、数据分析)主要依赖 MapReduce 等分布式处理框架,这些程序通常会扫描整个数据集。它们从文件的开头开始,一直读到结尾,将数据分块处理
架构
GFS 的架构如下图所示
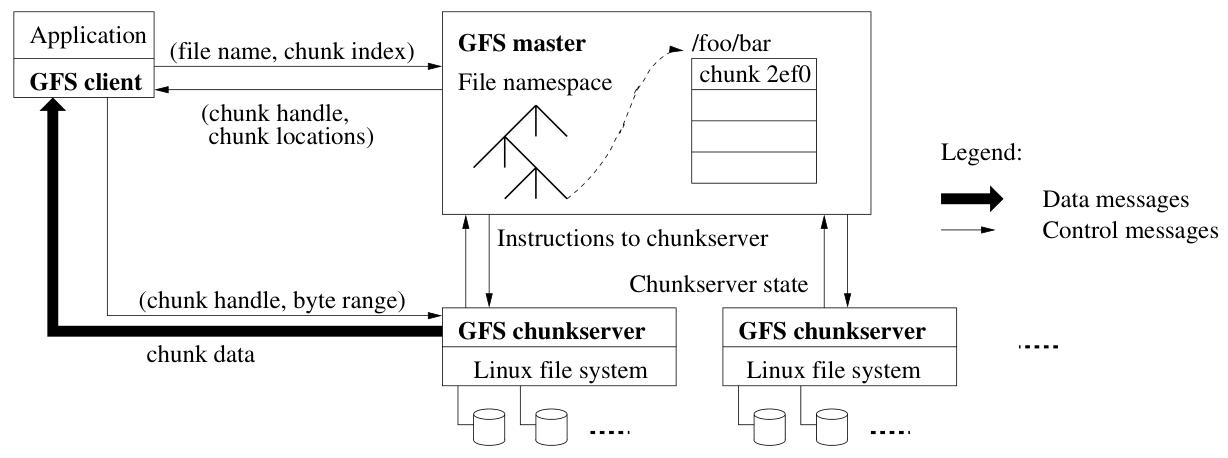
- 一个 Master 节点
- 元数据全部在内存中进行处理,但会以追加 LOG 的形式持久化到磁盘
- 块位置通过查询得到,无需存储
- 控制流和数据流分离避免主节点成为瓶颈
- 元数据全部在内存中进行处理,但会以追加 LOG 的形式持久化到磁盘
- 若干个 ChunkServer (默认三副本不同机架)
Q:为什么往磁盘中写 LOG,而不是用数据库的形式管理 LOG 呢?
A:磁盘可以对大量 LOG 直接进行一次性的追加写,这样只需要等磁盘旋转一次,但是数据库是 B 树,需要在随机位置写入,为了维护 B 树的索引结构,耗时比磁盘写更长注:这里实际上是牺牲读速度换取写速度的提升,这也带来了恢复时间的问题,为此 GFS 引入了 Checkpoint 机制
Checkpoint
Master 会定期将当前的内存状态序列化并写入磁盘,恢复时,Master 先加载最新的 Checkpoint,再回放该 Checkpoint 之后的少量 LOG。
ChunkSize
- 默认大小为 64 MB[1],远大于普通文件系统块,且创建后大小固定不变。
- 缺点:
- 小文件只由少量数据块组成,可能产生热点访问[2]
- 但 GFS 以大文件、顺序读为主
- 解决方案:允许客户端从其他客户端在这种场景下读取数据
- 碎片空间
- 延迟空间分配
- 小文件只由少量数据块组成,可能产生热点访问[2]
- ID 前缀压缩保证内存空间
读数据
对于读数据,一般是客户端首先有一个希望读取的文件名和希望从文件某个位置读取的偏移量,应用程序将这些发给 Master 节点,Mater 节点根据文件名找到对应的 ChunkHandle 数组,由于每个 Chunk 的大小是固定的,因此用偏移量除以 Chunk 大小就可以得到对应的分片的数组 ID,然后 Master 再从另一张表中获取该 ChunkID 对应的服务器位置信息,将服务器返回给客户端。也就是:
- 客户端向 Master 节点发送 文件名 和 偏移量
- Master 节点将 Chunk Handle 和 服务器列表 发送给客户端
Q: 这里返回的是一个特定的 Chunk 还是一个 Chunk 列表?
A: 基础的实现是返回对应的特定 Chunk,但是优化版是返回该 Chunk 后续数个 Chunk 以减少后续的交互(这里实际上后面的信息也在数组里了,因此没啥额外开销)
由于客户端可能多次从同一 Chunk 读取少量数据,因此客户端会缓存 Chunk 的映射关系,这样就可以不用去 Master 节点在此请求数据
Q:这里怎么保证客户端缓存的映射关系是正确的呢?
A:缓存有设置 timeout 时间,并且引入了版本号机制,当尝试访问服务器时,要带着版本号去访问
然后,客户端将 Chunk Handle 和偏移量发送给服务器,Chunk 服务器在磁盘上找到对应的数据读取并返回结果给客户端
写数据
GFS 在设计上为了适配谷歌的使用场景只支持了追加写。当我们要追加写的时候,我们必须知道文件的尾部在哪里。但是在 GFS 中,显然偏移量这一概念已经不适用了,这时,客户端可以向 Master 节点查询哪个块服务器保存了文件的最后一个块,也就是将裁决权交给 Master 节点,正如我们在以前交给操作系统一样。
对于写文件来说,必须要通过块的主副本写入,但是主副本也可能会不存在,这时 Master 节点就会找出所有存有 Chunk 最新副本的服务器(最新副本是指副本中保存的版本号与 Master 记录的版本号一致的副本),然后挑选一个作为主副本(Primary),并将消息下发给各副本。
Q:版本号更新顺序是怎样的?
A:Master 先落盘后更新。这是为了防止 Master 还没记就发生了崩溃Q: 什么时候版本号会增加?
A:版本号只在 Master 节点认为 Chunk 没有 Primary 时才会增加Q:为什么平时必须以 Master 的版本号为准,不能直接听 Chunkserver 的?
A: ChunkServer 如果发生故障导致版本号错乱,将不能裁决Q:那要是 Master 自己的硬盘故障,导致版本号乱了怎么办
A:当且仅当 Master 重启时,会询问 ChunkServer 版本号,如果有比自己大的,以 ChunkServer 为准Q:那如果刚好这两个服务器同时崩溃了,岂不是完了?
A:Master 节点也有远程副本,进一步降低概率,发生概率极端小
同时它还会给主副本一个租约 (lease),告诉主副本说接下来 60 秒,你将是主副本,60 秒后你必须停止成为主副本
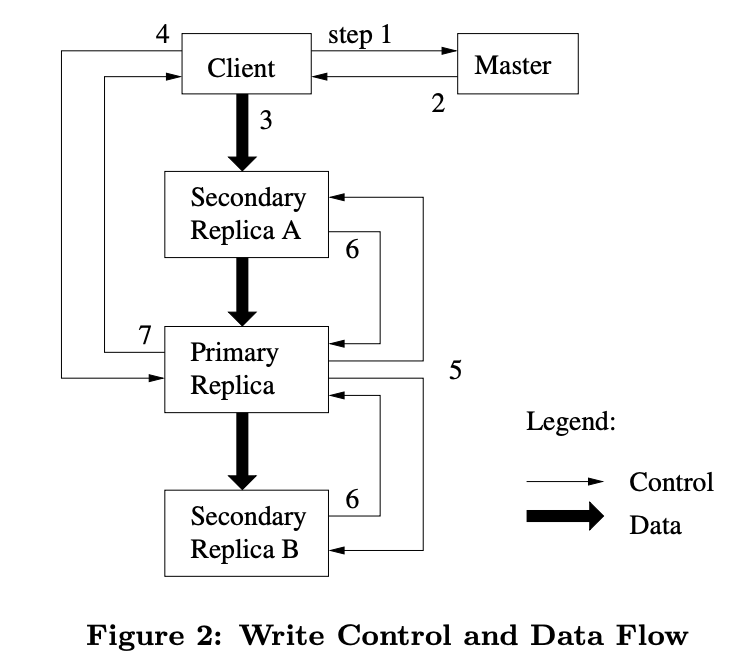
“While control flows from the client to the primary and then to all secondaries, data is pushed linearly along a carefully picked chain of chunkservers in a pipelined fashion.“
客户端会将要追加的数据发送给主副本和次副本 (Secondary),这些服务器将数据写入一个临时位置,直到所有服务器都返回了就绪消息,主副本会收到来自 Master 节点的追加确认请求,然后确保有 Chunk 足够空间后,将数据写入,并通知其余副本执行相同的操作。
Q:如果 Chunk 空间不足怎么办?
A:会进行填充垃圾数据 (padding),然后让次副本执行相同操作,然后返回一个空间不足,让客户端联系 Master 创建新 ChunkQ:为什么要做 padding 而不是分开写?
A:GFS 要保证写入操作的原子性,不能容忍Chunk 级别的不一致
对于次副本服务器,它们有概率会失败,返回一个失败的结果给主副本(或是没有返回结果),这时候主副本会向客户端返回一个写入失败。
Q:写失败后副本的状态如何恢复
A:不恢复,这是 GFS 的特性Q:如何判断数据的准确性
A:有一个 checksum 机制;以主副本为准;Master 会定时让短的同步长的;上层应用添加额外判断,详见一致性模型
如果客户端从 Primary 得到写入失败,那么客户端应该重新发起整个追加过程。
一致性模型
一个好的一致性系统是怎么样的?
对于具备强一致或者好的一致性的系统,从应用程序或者客户端看起来就像是和一台服务器在通信。尽管我们会通过数百台计算机构建一个系统,但是对于一个理想的强一致模型,你看到的就像是只有一台服务器,一份数据,并且系统一次只做一件事情。
你可以认为只有一台服务器,甚至这个服务器只运行单线程,它同一时间只处理来自客户端的一个请求。这很重要,因为可能会有大量的客户端并发的发送请求到服务器上。这里要求服务器从请求中挑选一个出来先执行,执行完成之后再执行下一个。
GFS 的实现
让我们看看如下场景,当我们追加数据时,假设 B 因为某些原因在一个副本中丢失了
| P | S1 | S2 |
|---|---|---|
| AB | AX | AB |
这时第二个客户端追加了数据 C,Primary 选择了偏移量,并将偏移量信息告知其他服务器,三个副本都在相同位置写入 C
| P | S1 | S2 |
|---|---|---|
| ABC | AXC | ABC |
接着,客户端返回了 B 的重试追加请求,这次我们追加成功了,于是便有以下情况
| P | S1 | S2 |
|---|---|---|
| ABCB | AXCB | ABCB |
更极端地,GFS 甚至会出现三个副本数据完全不一致的情况。
GFS这样设计的理由是足够的简单,但是同时也给应用程序暴露了一些奇怪的数据。这里希望为应用程序提供一个相对简单的写入接口,但应用程序需要容忍读取数据的乱序。如果应用程序不能容忍乱序,应用程序要么可以通过在文件中写入序列号,这样读取的时候能自己识别顺序,要么如果应用程序对顺序真的非常敏感那么对于特定的文件不要并发写入。
当然,对非并发的写入,也有可能会出现磁盘问题而导致的数据不一致,为此,GFS 使用 checksum 来校验,每 64 kb 的数据会计算一次 checksum 并加载在内存中,在返回数据时进行校验匹配,如果不匹配则上报数据损坏。
此外,由于只有主副本有分配偏移量的权利,因此我们在判断时以主副本的数据为准
GFS 的局限
GFS 只有一个主节点,这带来了如下问题:
- 随着增长,Master 节点的内存不足以维护所有的表单
- 除此之外,单个 Master 节点要承载数千个客户端的请求,客户端数量超过了单个 Master 的能力
- 另一个问题是,应用程序发现很难处理GFS奇怪的语义(GFS的副本数据同步问题)
- 最后一个问题是,Master 节点的故障切换不是自动的

