
MapReduce论文阅读
MapReduce 是什么
MapReduce 是谷歌提出的一种软件架构,旨在以分布式的方式去分解计算问题,常用于大规模数据集的并行运算。
MapReduce 是一种编程范式,使用 map 将大规模问题转换为子问题,然后用 reduce 将子问题的解汇总。
map 和 reduce 操作可以用下式概括:
map是数据的拆分者,其负责接收原始输入数据,按照业务逻辑进行拆分,生成程序中间的键值对数据list(k2,v2)- 一般来说,
map是无状态、并行的,每个map任务独立处理一部分输入数据,互不干扰
- 一般来说,
reduce是数据的合并者,负责接收map生成的中间键值对,按照中间键进行分组,对同一键的所有值进行聚合计算,生成最终结果,即list(v2)reduce任务的实例数量由用户定义,map生成的中间键值对会通过分区函数分配到不同的reduce实例,只有在期望全局唯一输出时,我们才会设置实例数量为一
简单的例子
MapReduce 最经典的例子就是单词计数任务,单词计数任务的两个函数定义如下:
func map(filename string, contents string) []mapreduce.KeyValue { |
更多应用
除了最简单的单词统计以外,还有很多的问题都可以套用MapReduce的模型解决。
- 分布式grep:Map函数在某一行匹配成功之后产生一个中间键值对,reduce函数将匹配结果简单合并。
- URL访问统计:Map函数根据每一条访问日志产生一个中间键值对
<URL,1>,reduce函数将URL的所有中间键值对的值相加,产生结果<URL,访问次数>。 - 反向网页链接图:当来源网页中出现一次目标链接,map函数产生一个中间键值对
<目标,来源>。Reduce函数合并相同目标的中间值,产生<目标,list(来源)>。 - 反向索引:Map函数解析文档后,产生如
<单词,文档编号>的中间键值对,然后reduce函数合并中间键值对,产生结果<单词,list(文档编号)>。最终结果组成一个反向索引,可以用于查询单词出现的文档。 - 分布式排序:Map函数根据每一条记录中参与排序的键取出,产生中间结果
<键,记录>,reduce函数则原样输出中间键值对即可。
MapReduce 实现
MapReduce 根据具体环境的不同有不同的实现方式,这里主要介绍谷歌使用的大型商用计算机集群中的实现方式,该集群有以下特点:
- 每台机器的内存通常在 2 - 4 GB
- 机器之间的带宽在 1 mb/s 到 1 gb/s 之间,但平均值远低于这个数
- 集群有上千台机器组成,因此机器故障较普遍
- 集群使用的磁盘很廉价,但使用了一个基于复制技术的分布式文件系统,保证了可用性和可靠性
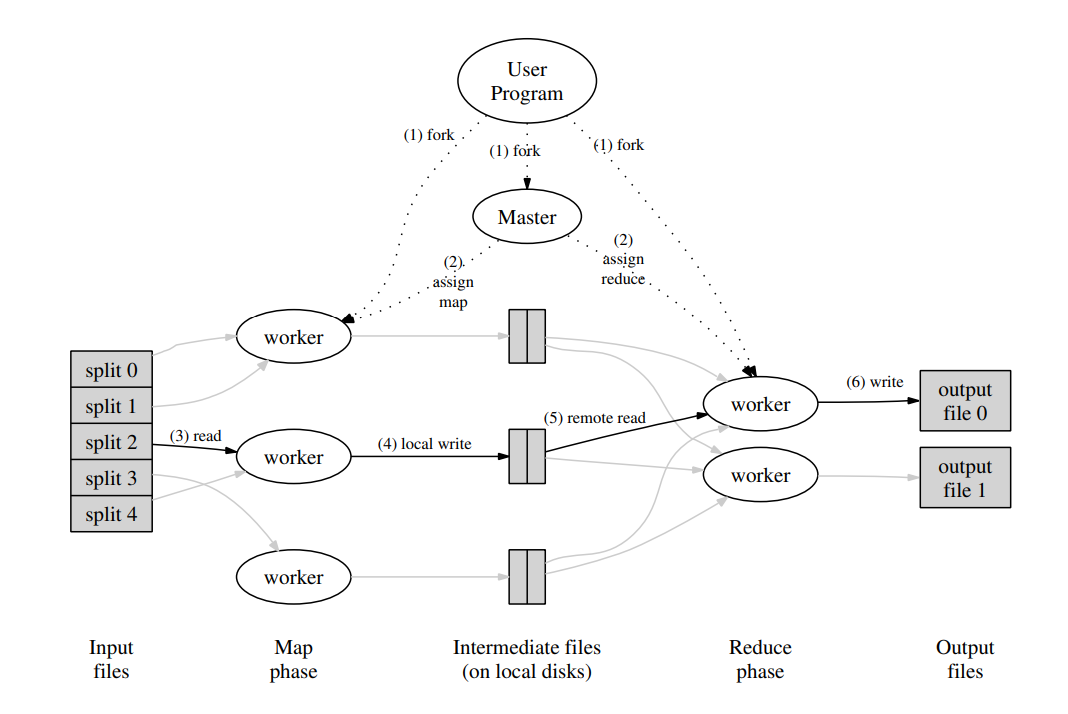
当用户程序调用 MapReduce 时,会发生如下内容:
- 用户输入数据被切分成 M 个片段(每个片段通常大小在 16 ~ 64 MB ),并在集群上启动了 MapReduce 的多个副本
- 其中有一个副本是特殊的 Master 节点,Master 节点负责分配工作任务给其余 Worker 节点,有 M 个 Map 和 R 个 Reduce 任务待分配
- 被分配 Map 任务的节点会读取相应输入分片的内容进行解析,通过 Map 函数计算出相应的中间键值对并将结果缓存在内存中。这些中间结果会定期被写入到本地磁盘中,并通过分区函数 (partitioning function) 划分为 R 个区域,并将位置信息发送给 Master 节点
- Master 节点会将这些位置转发给 Reduce 工作节点,当 Reduce 工作节点收到相关通知后,会通过远程调用读取来自 Map 工作节点本地磁盘的缓冲数据。当读取完全部的中间数据之后,将所有的键值对按照键顺序排序(如果数据量过大,中间结果过多,我们可能需要外部排序)
- key 很多种类的情况下,排序是有必要的吗?实践表明,数据分片后,往往同一 key 的数据在同一片 M 中。这体现了数据在空间上的局部性。
- Reduce 工作节点迭代访问所有独立的中间结果中的 K,将 K 和对应的一系列V中间结果传输给用户书写的 Reduce 函数,Reduce 函数输出的值会被写到该部分的结果文件中
- 当所有 Map 和 Reduce 函数结束执行时,Master 节点唤醒用户程序,此时在用户程序中的 MapReduce 调用结果返回
- 如果函数正确执行完毕,结果会被存储在 R 个输出文件中(每个 Reduce 任务一个输出文件)
容错机制
Worker 故障
- Master 会定期 Ping Worker 节点,确认 Worker 在线,如果在一定时间段内收不到响应,则将该 Worker 标记为 Failed,该工作节点已完成的所有 Map 任务都会被重置为 Idle 状态以在其他节点上被调度,同理,该工作节点上正在进行的 Map 和 Reduce 任务也会被重置
- 这是因为如果该 Worker 故障,那么存储在该 Worker 本地磁盘的 Map 任务结果也会无法访问,因此已完成的 Map 任务也要重做
大规模 Worker 出错
- 没有应对机制
Master 故障
- Master 会定期将状态保存到磁盘,崩溃后直接利用保存的状态恢复,此外,用户侧也可以自行决定是否要重试,也可以直接终止 MapReduce 任务
故障的后果
用户的 Map 和 Reduce 函数的结果具有确定性
用户编写的 Map/Reduce 函数输入固定时,输出必然唯一且固定 —— 无论执行多少次、在哪个机器上执行,结果都完全一致
即使出现错误,分布式执行的输出与 “无故障的串行执行” 结果完全一致。
实现逻辑:依赖 Map 和 Reduce 任务输出的原子提交机制。
- 任务执行时,输出先写入私有临时文件(Map 任务生成 R 个临时文件,Reduce 任务生成 1 个临时文件)。
- 任务完成后,Map 任务向 Master 上报临时文件位置,Reduce 任务原子化重命名临时文件为最终输出文件。
- 若同一任务因故障被重复执行,原子操作会保证最终仅保留一次有效执行的结果,避免数据冲突。
- 如当一个 Map 任务结束时,会通知Master,并把文件的地址携带给Master
- 如果 Master 收到了已经结束的 Map 任务的通知,那么会忽略这个消息
- 否则,会记录这些文件的地址到主存里。
- 如当一个 Reduce 任务结束时,Reduce Worker原子的重命名文件,所以即使并发最终也只会有一个最终的文件。
用户的Map和Reduce函数结果不具有确定性
输出仍具合理性,但不同 Reduce 任务的结果可能对应不同串行执行的快照
比如 Reduce 任务 可能读取 Map 任务 M 的第一次执行输出,而 Reduce 任务 可能读取 M 故障后重新执行的输出,导致 和 的结果分别对应两次不同的串行执行结果,但单个 Reduce 任务的输出仍符合其对应的串行执行逻辑
任务粒度
- 我们将 Map 阶段划分为 M 个片段,将 Reduce 阶段划分为 R 个片段。理想情况下 M 和 R 应该远远大于 Worker 机器的数量,这样能够动态负载均衡,并且加速了工作节点的恢复。
- 的调度抉择, 的内存数据结构维护
- R 通常由用户限制,因为每一个 ReduceTask 往往输出一个分离的文件
- 我们通常选择 M 使得每一个输入数据的分块大概在 16MB - 64MB 之间,并且让 R 是 Worker 机器数量的一小倍,比如 M=200000,R=5000,使用 2000 台机器
备份任务
-
集群中的部分机器可能因为各种原因成为“掉队者”,这些机器在执行最后几个任务时的速度极慢,会严重拖慢整个 MapReduce 任务的执行时间
-
我们有一个通用的机制来缓解慢工作者的问题。当一个 MapReduce 操作接近完成时,Master 节点会安排对剩余的正在进行中的任务执行一个备份任务(对已有任务的复制)。只有当主执行或备份任务执行完成时,任务才被标记为已完成。我们调整了这个机制,使得它通常只会增加操作使用的 CPU 资源的很少部分。
改进
- Partitioning 函数:对于中间结果特殊的分割
- Order 保证:保证在一个分区内,key/value 对是按照递增顺序的,能够支持高效的随机访问。
- Combiner 函数:在 Map 任务后,送到 Master 前,允许使用 Combiner 函数进行一些合并操作,来加速一些 MapReduce 操作。
- 跳过坏的记录:有时因为用户代码的问题,导致 MapReduce 操作在中途固定的地方会 Crash,于是我们允许其略过这个 BUG,从而避免程序崩溃。
- 本地执行调试:为了帮助调试,提供一个可选的 MapReduce 实现,是在本地去线性进行的,可以方便的进行调试执行。
- Status 信息:Master 内置一个 HTTP 服务器,并且导出了一系列页面,显示计算的进度,比如多少任务已经完成等等、
- Counter:提供一个计数器来记录特定事件的发生次数。