
论文阅读:MapReduce
MapReduce 的目的
当时互联网刚刚兴起,需要一套系统来处理海量的数据计算问题,同时要做到简单易用,且有足够的容灾能力
创新点
提出了一种新的编程范式,使用 map 将大规模问题转换为子问题,然后用 reduce 将子问题的解汇总,将所有任务抽象为了这两个动作。
map 和 reduce 操作可以用下式概括:
map是数据的拆分者,其负责接收原始输入数据,按照业务逻辑进行拆分,生成程序中间的键值对数据list(k2,v2)- 一般来说,
map是无状态、并行的,每个map任务独立处理一部分输入数据,互不干扰
- 一般来说,
reduce是数据的合并者,负责接收map生成的中间键值对,按照中间键进行分组,对同一键的所有值进行聚合计算,生成最终结果,即list(v2)reduce任务的实例数量由用户定义,map生成的中间键值对会通过分区函数分配到不同的reduce实例,只有在期望全局唯一输出时,我们才会设置实例数量为一
简单的例子
MapReduce 最经典的例子就是单词计数任务,单词计数任务的两个函数定义如下:
func map(filename string, contents string) []mapreduce.KeyValue { |
How To Work?
MapReduce 的实现方式如下图所示
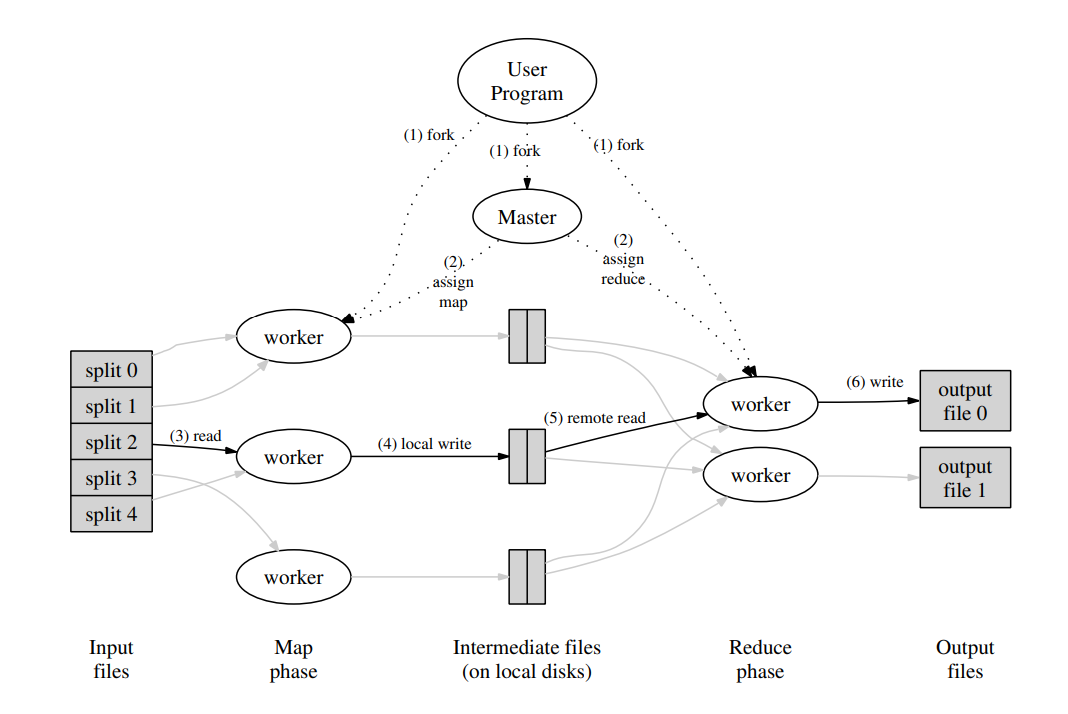
- Master 节点接受来自用户的 Map 和 Reduce 任务,将这些任务分配给 Worker 节点
- 中间数据落盘,Map Worker 节点将工作结果写入本地磁盘,并通知 Master 位置
- 当 Reduce 工作节点收到相关通知后,会通过远程调用读取来自 Map 工作节点本地磁盘的缓冲数据。当读取完全部的中间数据之后,将所有的键值对按照键顺序排序(如果数据量过大,中间结果过多,我们可能需要外部排序)
- key 很多种类的情况下,排序是有必要的吗?实践表明,数据分片后,往往同一 key 的数据在同一片 M 中。这体现了数据在空间上的局部性。
- 如果函数正确执行完毕,结果会被存储在 R 个输出文件中(每个 Reduce 任务一个输出文件)
容错机制
Worker 故障
- Master 会定期 Ping Worker 节点,确认 Worker 在线,如果在一定时间段内收不到响应,则将该 Worker 标记为 Failed,该工作节点已完成的所有 Map 任务都会被重置为 Idle 状态以在其他节点上被调度,同理,该工作节点上正在进行的 Map 和 Reduce 任务也会被重置
- 这是因为如果该 Worker 故障,那么存储在该 Worker 本地磁盘的 Map 任务结果也会无法访问,因此已完成的 Map 任务也要重做
Master 故障
- Master 会定期将状态保存到磁盘,崩溃后直接利用保存的状态恢复,此外,用户侧也可以自行决定是否要重试,也可以直接终止 MapReduce 任务
备份任务
-
集群中的部分机器可能因为各种原因成为“掉队者”,这些机器在执行最后几个任务时的速度极慢,会严重拖慢整个 MapReduce 任务的执行时间
-
我们有一个通用的机制来缓解慢工作者的问题。当一个 MapReduce 操作接近完成时,Master 节点会安排对剩余的正在进行中的任务执行一个备份任务(对已有任务的复制)。只有当主执行或备份任务执行完成时,任务才被标记为已完成。我们调整了这个机制,使得它通常只会增加操作使用的 CPU 资源的很少部分。
缺陷
不适合低延迟/迭代计算,每次 Map 的中间结果都要写磁盘,IO 开销极大。
参考
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 墨池码窖 | Sentixxx's Blog!

评论